听了那么多逼哥,逼哥到底再讲什么?
00x1 前言
作为逼粉,不想多逼逼,用逼哥的歌词来分析逼哥到底在讲什么,歌曲都是大家熟知的那些歌,大约1.2W字吧。做这个主要是想玩玩分词,第三方类库 Jieba。其实可以爬网易云上的,但是我为什么没有这样做呢?因为不会。。。

00x2 环境及第三方类库
数据分析嘛,毋庸置疑,Python。安装jieba,可以直接
1
| easy_install jieba 或者 pip install jieba
|
但是我的总会出错,可能是因为我本地装了两个版本的python吧,于是我下载了jieba解压之后运行
下载地址:https://pypi.python.org/pypi/jieba/
00x3 源码以及歌词文本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| import xlrd #操作Excel import jieba # 分词包 import numpy #统计 import codecs #字符编码,读取文件 import pandas #数据处理 file = codecs.open("C:\\李志歌词.txt",'r','gbk') content = file.read() file.close() segments = [] segs = jieba.cut(content) for seg in segs: if len(seg)>1: segments.append(seg) segmentDF = pandas.DataFrame({'segment':segments}) df = segmentDF.groupby("segment")["segment"].agg({"计数":numpy.size}).reset_index().sort(columns = ['计数'],ascending = False) print(df.head(100)) df.to_excel('李志-分词.xls', sheet_name='sheet1')
|
歌词下载页:歌词下载
运行结果:
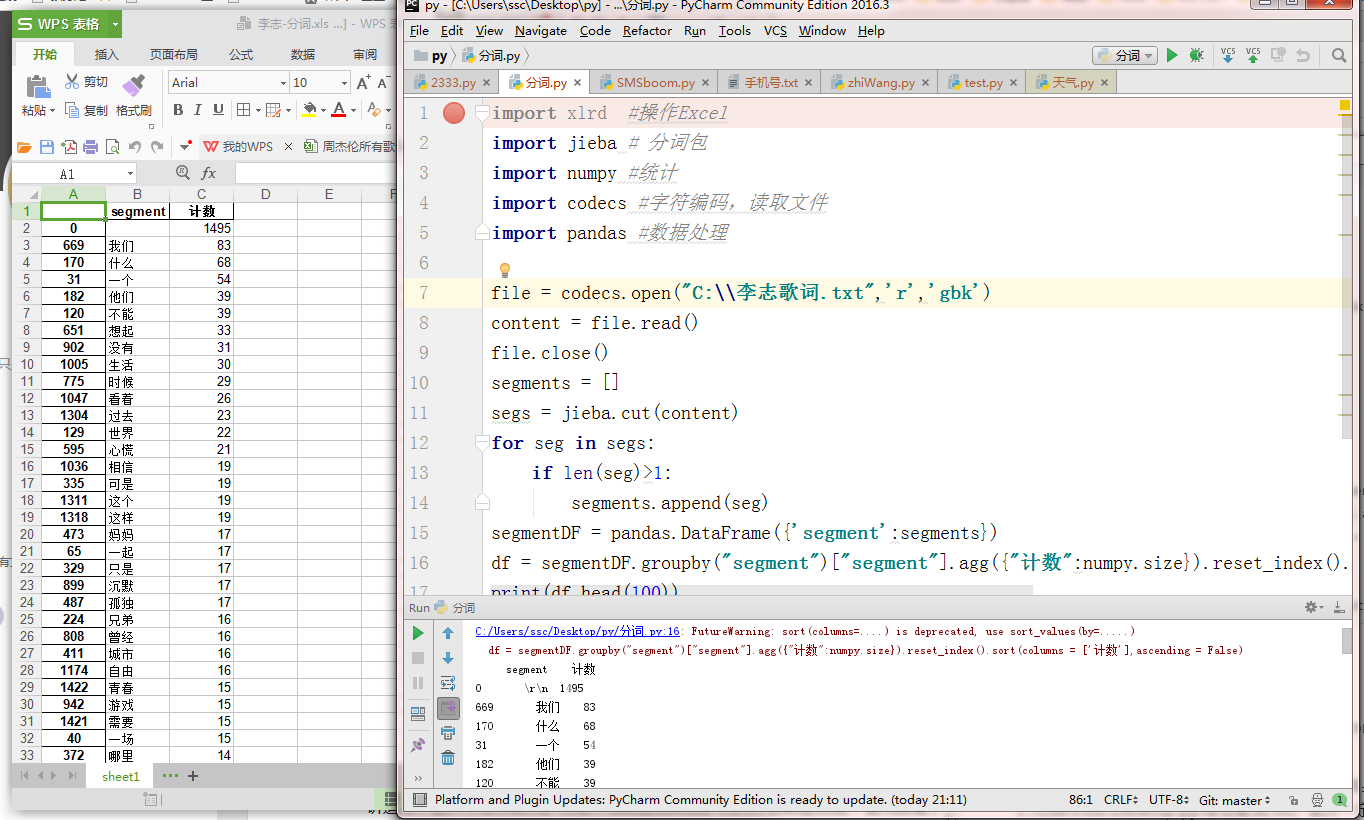
这让人心慌啊!这能分析出来个鸡毛呀?对不起,我又骗了大家。
00x4 可能遇到的问题
- 文本的编码问题,可能出现 UnicodeDecodeError 报错,可以把gbk改为 utf-8试试。
- 文本路径存放问题,建议像我一样存放在C盘,如果你放在桌面,例如:C:\Users\ssc\Desktop\py\李志歌词.txt,运行一定会报错,因为目录下的\U会被编译器认为是八进制。
00x5 最后想说
jieba还是蛮强大的,支持多种分词模式,而且还有多个语言版本。详细见 ReadME
最后,怀念过去 1s(逃

